正在更换,请稍后
最新粉丝
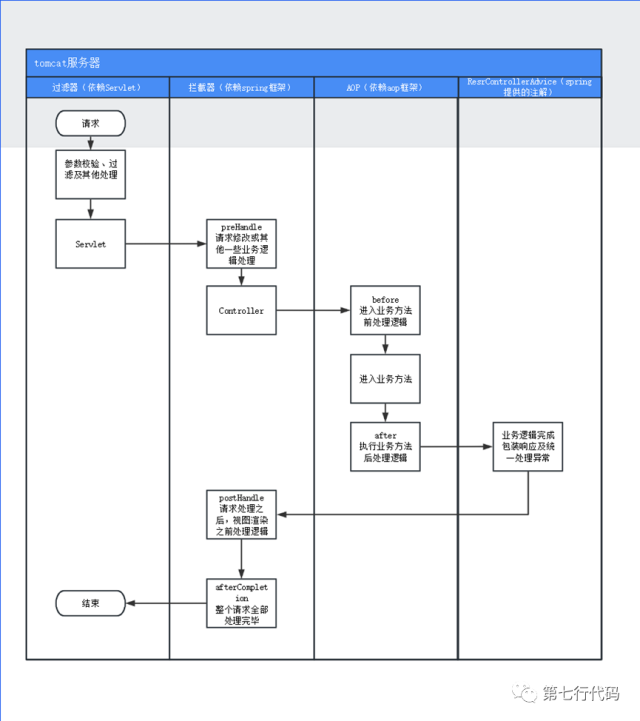
使用自定义过滤器进行请求前置处理并做日志打印和服务鉴权。
选择多线程的原因,就是因为快。
实现的功能,就不要轻易自己重复造轮子,或者引入三方中间件。
对于MySQL数据库来说的话,一般的对象都是一个事务一个事务来说的。
使用不同方式实现词频统计。
大数据篇-Spark安装部署及应用。
分布式计算引擎Spark简析。
group by 的时候,case when放在聚合函数中进行聚合函数的操作。
海量数据存取技术架构。
由于参加秒杀的商品售卖价格非常低,基本都是“抢到即赚到”,成功下单后却不付款的情况非常少。
堆内存中存储着所有new出来的对象,是所有线程共享的区域。
关系型数据库以MySQL为例,单机的存储能力、连接数是有限的,它自身就很容易会成为系统的瓶颈。
新知号认证
公告
此号主要用于分享java、微服务、大数据等等相关技术内容,整体基调较低,推荐有编程基础的读者阅读,文章的内容主要是本人自身在学习过程中遇到的比较重要、难理解、或者比较有趣的技术,微信公众号同名。
联系方式
TA的关注 1人
 新知号认证
新知号认证



 刘s
刘s  bluer
bluer  杨明科
杨明科  刀刀得
刀刀得  虎魄
虎魄  chokarkar
chokarkar  Cuckoo
Cuckoo  Zigar
Zigar